[Summary]
- 본 논문에서 제안하는 방법인 DeiT는 vision transformer (ViT)을 distillation으로 학습시킨 image classification 모델이다. DeiT의 main contribution은 ViT 모델을 학습시키는 방법에 있기 때문에, 모델의 구조적인 차별성은 거의 없다 (사실 전혀 없다고 봐도 무방한 것이 ViT에서 channel 숫자만 바꾸는 정도의 수정만을 가하였다).
- DeiT는 Distillation 방법을 통해서 기존 ViT 모델의 한계를 극복할 수 있음을 주장한다. ViT의 문제점은 Transformer의 구조적인 한계로 인해 image 데이터를 학습할 때 CNN과는 달리 이미지 처리에 유리한 inductive bias (locality와 translation equivariance 와 같은 CNN 모델 고유의 특징)를 학습하지 못한다는 점에 있다. ViT 논문에서는 이러한 페널티를 극복하기 위해서 대량의 데이터를 학습시키면 SoTA CNN모델에 근접하는 성능을 낼 수 있다고 주장을 하는데, ViT를 학습시키기 위한 데이터는 실로 방대하기에 일반적인 장비로는 감히 학습하는 것은 엄두도 못낼 크기이다.
- DeiT에서는 distillation을 이용하여 ViT가 CNN의 inductive bias를 학습할 수 있음을 주장하며, 이렇게 하면 방대한 데이터 없이도 ViT를 GPU 4장으로 3일안에 학습시킬 수 있음을 실험적으로 보인다. 성능적인 측면에서도 아직까지는 Transformer에 의한 classification 성능이 CNN을 능가하지는 못하지만, 그 GAP이 충분히 좁혀질 수 있으며 앞으로 제안될 연구들에서는 CNN모델과 필적하는 Transformer 모델들도 등장할 것이라는 기대를 할 수 있다.
[Strengths]
Interestingly, with our distillation, image transformers learn more from a convnet than from a another transformer with comparable performance.
- 재미있는 발견이라고 생각한다.
We have observed that using a convnet teacher gives better performance than using a transformer.
- 반복하여 주장하고 있다.
Furthermore, when DeiT benefits from the distillation from a relatively weaker RegNetY to produce DeiT⚗, it outperforms EfficientNet.
- 결국 요약하자면, DeiT 기본 모델만 가지고도 Transformer로 imagenet task 성능을 많이 올렸는데, distillation까지하면 efficientNet까지 능가할 수 있다는 이야기이다.
[Weaknesses]
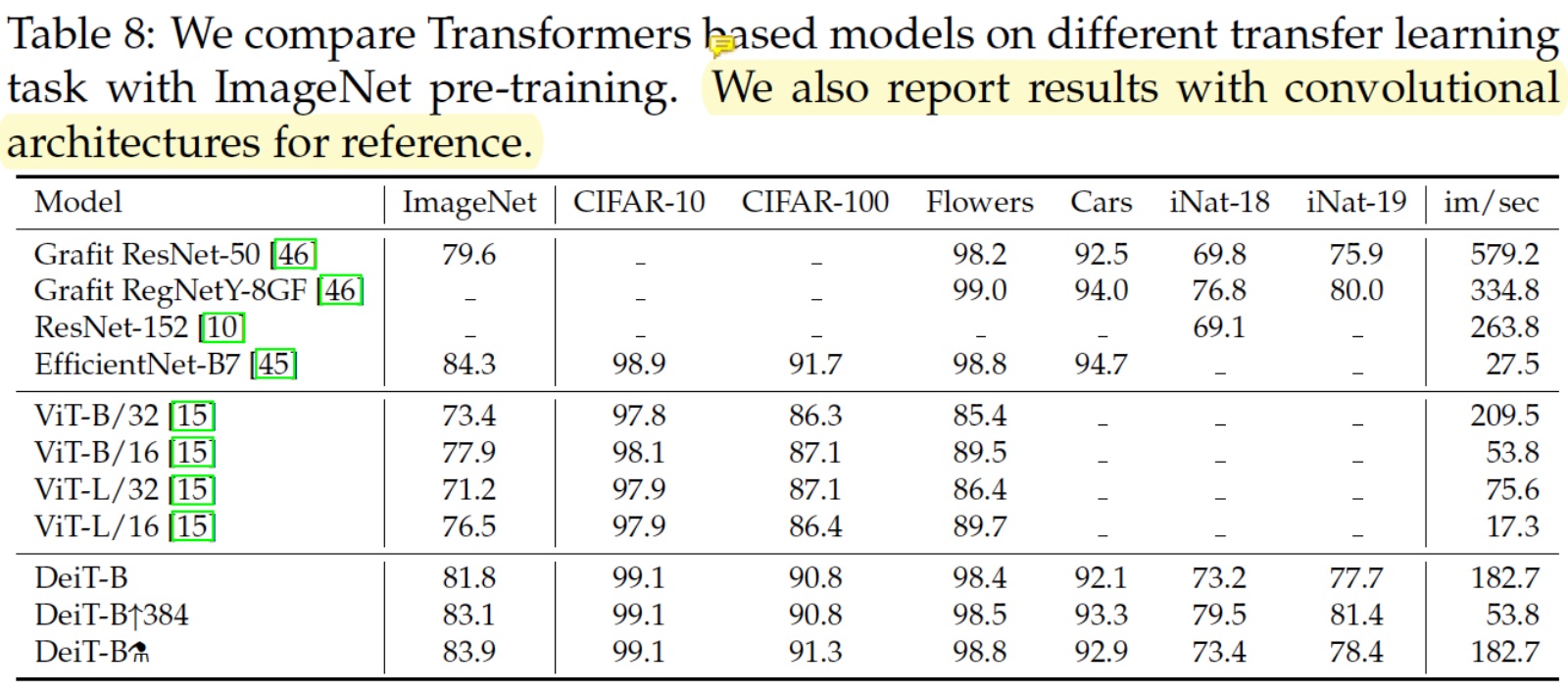
- efficientnet의 성능이 조금더 앞선다. 논문에서는 마치 DeiT가 throughtput 측면에서 efficientnet보다 앞서는 것처럼 서술하고 있지만, table6의 결과를 보면 efficientnetb0도 deit ti 보다 더 높은 성능에 더 높은 throughtput을 보임을 알 수 있다. 따라서 아직까지는 Transformer 기반의 모델이 성능적인 측면에서 convnet을 이긴다고 할 수는 없겠다.
[Interesting things]
The transformer block described above is invariant to the order of the patch embeddings, and thus does not consider their relative position.
- 2021 CVPR에 제출된 리뷰 페이퍼 중, 이미지에 존재하는 target object를 랜덤으로 크롭하여 contextual consistency를 유지하는 내용이 있었는데, 어쩌면 VIT는 비슷한 맥락으로 주변 patch와의 relation이 아닌 object 자체에 대한 특징을 잘 형성하게 되는 것일지도 모르겠다.
Touvron et al. [47] show that it is desirable to use a lower training resolution and fine-tune the network at the larger resolution.
- pre-training은 low resolution으로 하고, fine-tuning은 high resolution으로 하는 것이 바람직하다는 것이 논문으로 발표된 줄은 몰랐다.
Hard-label distillation
- Hard-label distillation에서는 KL loss 항이 CE로 치환된다.
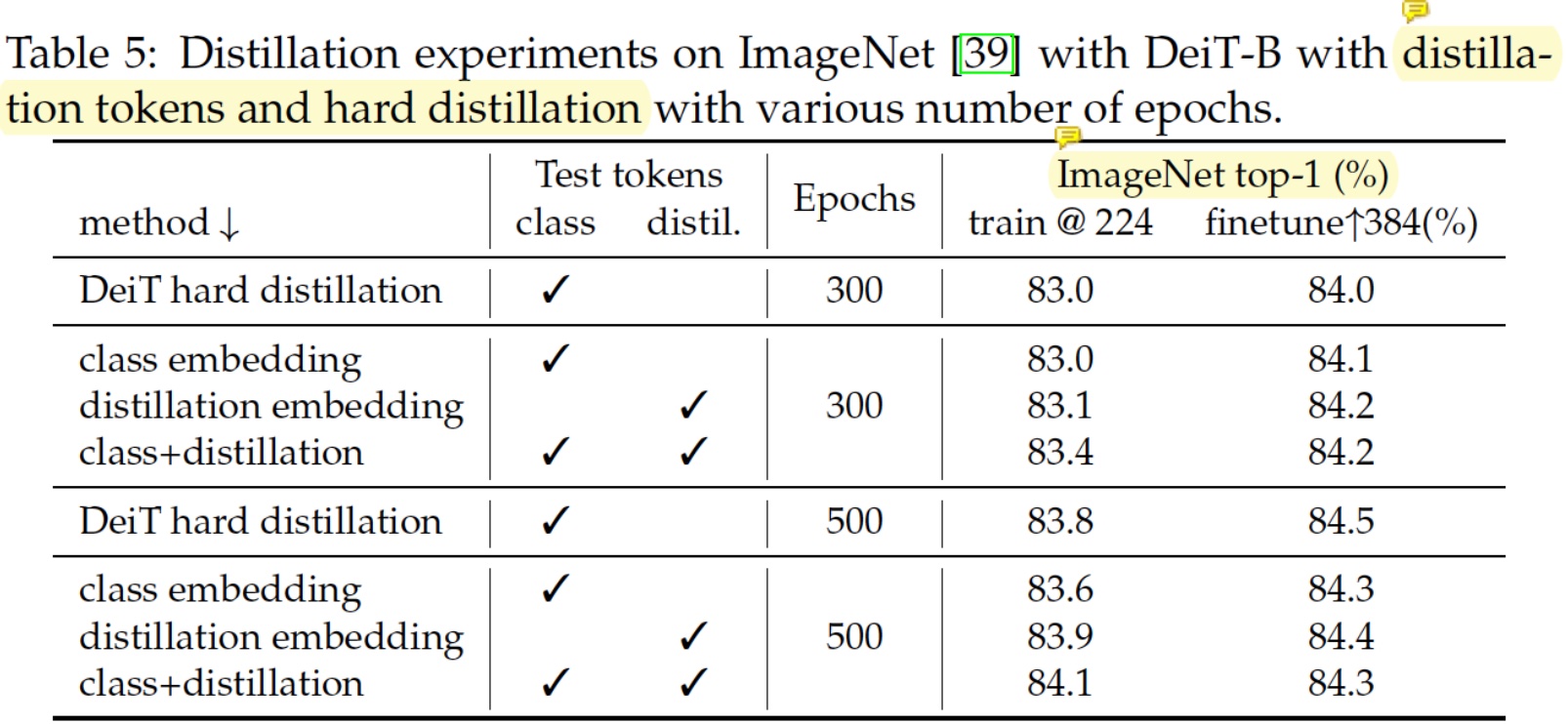
- DeiT의 두 가지 핵심 요소에 대한 실험 결과를 보이고 있다.
- Fine-tuning 안 했을때는 제안하는 distillation 방법이 근소하게 앞서는데, fine-tuning 하면 오히려 뒤집히는 효과가 발생한다. 순수 distillation 효과만 보면 아주 근소하게 효과가 있다고 봐야하나?
[17] Priya Goyal, Piotr Doll´ar, Ross B. Girshick, Pieter Noordhuis, LukaszWesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- minibatch size에 따른 정확한 learning rate 계산하는 법이 나오는듯?
[Citation]
Paper link: https://arxiv.org/abs/2012.12877?fbclid=IwAR3YDfOm_795KDp2VmGHfFz-ZLH0cLhOatEq-r2HeN0t6CQGXz9VDdglSaE Original blog: https://ai.facebook.com/blog/data-efficient-image-transformers-a-promising-new-technique-for-image-classification/