DETR: End-to-End Object Detection with Transformers
[Summary]
본 논문은 object detection을 set prediction의 관점에서 접근하여, Transformer로 구현하는 방법을 소개한 논문이다. 우선 object detection에서의 set prediction이란, target object와 prediction이 1대1로 매치가 되도록 모델을 동작시키는 것이다. DETR은 target object와 prediction이 1대1로 매치하기 위해서 한 가지 영리한 트릭을 사용하는데, target class 외에 추가로 no object라는 class를 정의하여 모델을 학습시킨다.
DETR은 일반적으로 사진 속에 존재하는 target object 보다 더 많은 prediction을 하도록 설계되었는데, 실제로 target object 가 존재하는 부분에서는 해당 object의 class와 bbox를 output으로 도출하고 그 외의 지역에 대해서는 no object 라는 prediction 값을 output으로 내놓게 된다. Set prediction이라는 표현이 해당 논문에서 매우 중요한 의미로 사용이 되는데, 그것은 DETR이 기존의 detector와는 다르게 한 object에 대해서 중복없이 단 한번의 prediction만을 하기 때문이다. 이것을 가능하게 하는 학습 방법이 hungarian matching이며, DETR이 image query를 통해 prediction을 할 때 같은 영역을 보지 않도록 동작하게 만든다.
DETR이 가능하게 하는 또 한가지 중요한 요소는 Transformer를 사용했다는 것에 있다. 우선 Transformer를 구성하는 encoder 단에서는 self-attention을 부여하여 입력이미지의 전체적인 문맥을 학습하고, 각각의 target을 인지하도록 한다. 이어서 decoder 단에서는 multi-head attention을 활용하여 target을 구성하고 있는 detail에 집중할 수 있도록 하였다. 결국 DETR은 encoder-decoder 형태의 transformer와 hungarian matching으로 구현된 기존 detector들과는 다른 접근 방식으로 object detection 문제를 풀 수 있었으며, 비록 성능은 faster rcnn과 비교되는 수준이지만 (최신의 더 좋은 detector가 많음에도 불구하고), 충분히 연구적으로 가치가 있는 논문이라고 생각한다. 다만, 기존 detector들의 필수 post-processing 방법인 NMS가 DETR에서는 필요가 없는 것처럼 서술하고 있지만, 실험적인 근거가 매우 약하다는 점에서 약간의 아쉬움이 있다.
[Introduction]

Facebook AI에서 발표한 DETR은 End-to-End로 학습가능한 DEtection 을 위한 TRasnformer를 제안함으로써
ECCV 2020의 accepted paper list가 공개되지 않은 시점에서도 ML 및 CV 커뮤니티에서 뜨거운 이슈가 되었다.
이 논문이 주목을 받게 된 것은 기존 방법들과 차별된 두 가지 이유가 있었기 때문이다.
- Detection task를 Natural Language Processing (NLP)의 관점에서 접근하였다.
- Anchor와 Non-maximum Suppression (NMS)과 같은 heuristic에 의존하지 않는다.
우선은 Sequential 데이터 분석에 유리하다고 알려진 Transformer를 Image 데이터에 적용하는 시도 자체가 신선하다는 생각이 든다. Transformer를 detection task에 적용하기 위해서는 기존의 work에서 몇 가지 요소를 제거하고 새로운 장치를 도입해야만 했을 것이다. Hungarian matching이 바로 그것인데 이는 nlp에서 word embedding이 특정 단어와 매칭되듯이, image 내의 target object와 이를 표현하는 image query라는 일종의 embedding vector가 항상 1:1로 매칭되도록 하는 효과를 준다. 그 결과 anchor와 NMS 도움이 필요없게 되는 것이다. 사실 anchor와 NMS는 대부분의 Object Detection 방법들에서는 필수적으로 사용되는 방법이었지만, 아이러니 하게도 data-driven을 지향하는 머신러닝 트렌드와는 맞지 않게 heuristic 그 자체다. 저자들은 이 부분을 지적하며 DETR의 우수성을 강조한다.
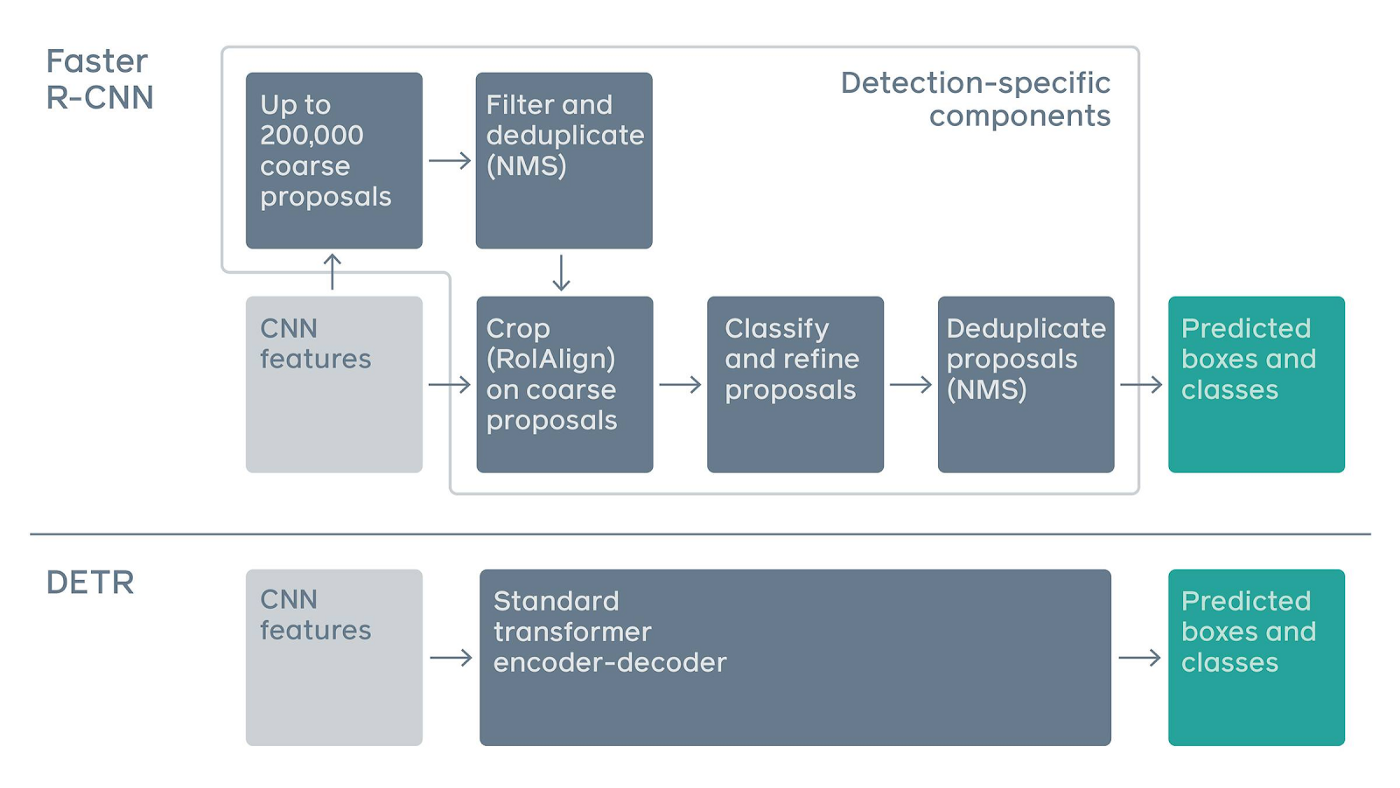 Fig.1 Faster RCNN과 DETR의 구조적 차이 비교 (source: https://medium.com/swlh/one-stop-for-object-detectors-2c99daa08c50)
Fig.1 Faster RCNN과 DETR의 구조적 차이 비교 (source: https://medium.com/swlh/one-stop-for-object-detectors-2c99daa08c50)
Fig.1은 Faster RCNN과 DETR의 구조적 차이를 도식화하여 표현한 것이다. Faster RCNN이 object를 detection 하기 위해서는 CNN feature를 추출한 뒤 region proposal, NMS, 그리고 RoI Align과 같은 domain specific한 복잡한 과정을 거치는 반면, DETR은 이 모든 과정을 Transformer에 맡겨버린다. 저자들은 Detection 모델이 학습을 잘하였다면 기존 detection 방법들에 적용하던 heuristic한 과정들을 추론 과정에서 모두 녹여낼 것이라는 가정을 하였을 것이다. (무책임해 보일 수 있지만 실험 결과를 보면 의도한대로 잘 학습이 되는 것 같다.)
모델의 구조가 간단하니 DETR은 학습 과정도 End-to-End로 간단하게 구현이 가능하다는 것도 장점이라 할 수 있다. Faster R-CNN을 학습시키기 위해서는 region proposal network과 detector 몇번의 epoch 마다 번갈아가면서 학습을 시켜줘야한다. (저자들의 original 코드 참조)
그러나 DETR에도 몇 가지 개선이 필요한 부분이 있다. 첫째는 학습 시간이다. 전체적인 파이프라인은 간단하지만, Transformer 자체는 복잡한 모델이다. (Transformer에 대한 자세한 설명은 다음 포스팅에서 다룰 예정이다.) Self-attention을 포함한 encoder-decoder 구조를 하고 있어 학습해야하는 파라미터가 많아, V100을 16장을 쓰고도 학습시간이 3일이나 걸린다고 한다.
둘째는 small object (COCO에서 정의한 small object target)에 대한 detection 성능이 기존 SOTA에 미치지 못하는 점이다. 저자들은 Hungarian Matching과 self-attention 구조가 large object의 포착에는 유리하지만, small object 포착을 위해서는 개선이 필요하다고 밝히고 있다.
이러한 한계점이 존재함에도 나는 DETR이 object detection에 새로운 패러다임을 제시하는 milestone급의 논문이 아닐까하는 생각이 든다. 특히, DETR의 decoder attention을 가시화한 Fig.2에서 두 마리의 코끼리 상당 부분 겹쳐 있음에도, 어떤 다리가 어느 코끼리의 것인지 구분할 수 있음을 보여주는데, 코끼리의 형상을 완벽하게 학습해내지 않고는 절대 불가능한 task라는 생각이 든다. 그 옆에 있는 얼룩말의 예시에서도 비슷한 특징이 보인다.
 Fig.2 DETR의 decoder attention을 가시화한 예시. 모델은 주로 object의 외곽 부분에 집중하고 있다. 각각의 object에 대한 prediction 결과는 각각 다른 color로 표현된다.
Fig.2 DETR의 decoder attention을 가시화한 예시. 모델은 주로 object의 외곽 부분에 집중하고 있다. 각각의 object에 대한 prediction 결과는 각각 다른 color로 표현된다.
Comments