[Summary]
- https://arxiv.org/pdf/1901.03353.pdf
- RetinaNet에 mask prediction head를 추가한 instance segmentation 모델. 세 가지 측면에서 contribution이 있음
- Mask Prediction Module
- 구조적으로 간단한 수정으로 mask prediction 가능
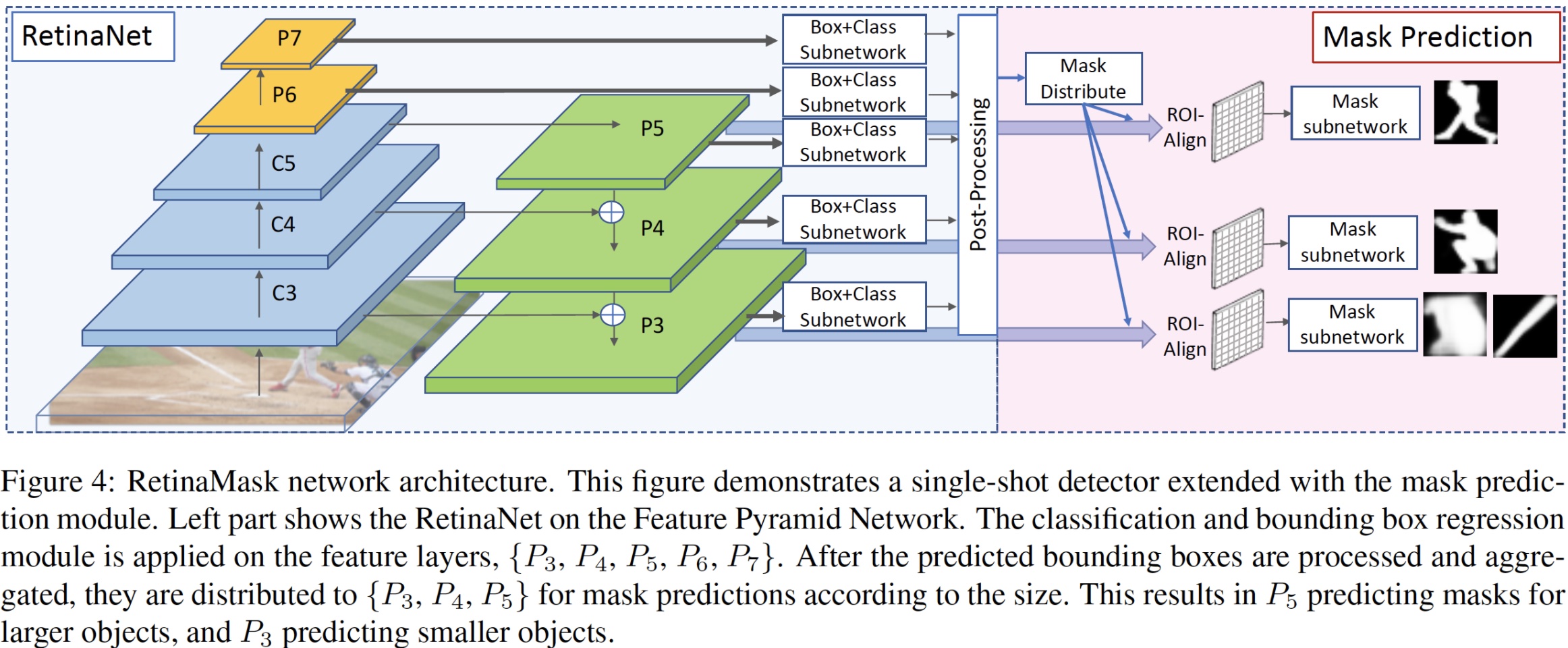
- box regression 결과 중 top N score를 뽑고, 거기에 mask prediction
- P3~P7까지는 box prediction, P3~5는 mask prediction에 사용
- mask prediction 시 layer 수를 늘려도 성능은 비슷했다고 함
- Self-Adjusting Smooth L1 Loss
- robustness를 개선하기 위하여 self-adjusting loss 추가
- Detector 에서 많이 사용하는 smooth L1 loss에는 L1과 L2의 적용 범위를 결정하는 beta parameter가 fixed 되어 사용되는데, 이것을 self-adjusting 되도록 구현함
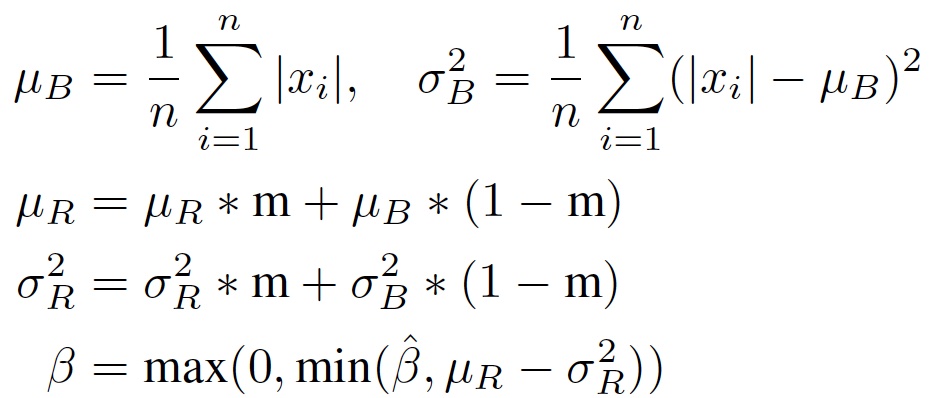
- smooth L1 loss
- ‘a point beta splits the positive axis range into two parts: L2 loss is used for targets in range [0; beta], and L1 loss is used beyond beta to avoid over-penalizing outliers.’
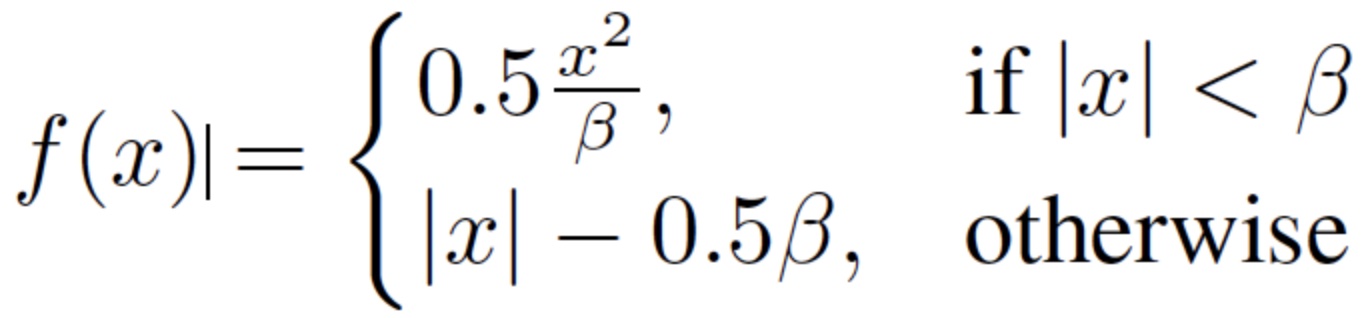
- 실험 결과 상으로는 아주 약간의 성능 이득(AP 0.4~1.2)이 있는 것으로 보임
- Best Matching Policy
- Anchor의 형태에 의해서 target이 positive example에 포함되지 못하는 문제가 있음을 제시하며, iou threshold를 조정하도록 제안함
- 실험 결과에 따르면 iou threshold가 0 이상 일때, 즉, 조금이라도 gt와 겹치는 anchor를 모두 positive example로 간주했을때 detection 성능이 가장 높았다는 이야기
[Strengths]
- 학습된 retinanet의 weight를 재활용 할 수 있음
- 속도 측면에서 mask rcnn 보다 빠를 것으로 예상됨
[Weaknesses]
- 논문 상에서 detection 성능은 retinanet보다 향상되는 것을 확인하였지만 (mask label의 효과일 듯), segmentation 성능은 mask rcnn이 더 높은 것으로 확인됨
- 논문이 publication 되지 않은 상태라 결과에 대한 신뢰도가 낮음
[Codes]
- https://github.com/chengyangfu/retinamask (pytorch)
- 유사 구현체: https://github.com/fizyr/keras-maskrcnn
- 유사 구현체는 mask rcnn의 rpn 대신 retinanet을 사용한 버전임. 엄밀히 따지면 retinamask는 아니지만 거의 유사한 동작 원리를 가지고 있는 것 같아서 참고하기에 좋을 것 같음
Comments