[Summary]
- https://arxiv.org/abs/1911.06667
- Anchor free detector인 FCOS의 detection 결과에 mask prediction을 하도록 segmentation branch인 spatial attention-guided mask (SAG-Mask) branch를 추가한 모델
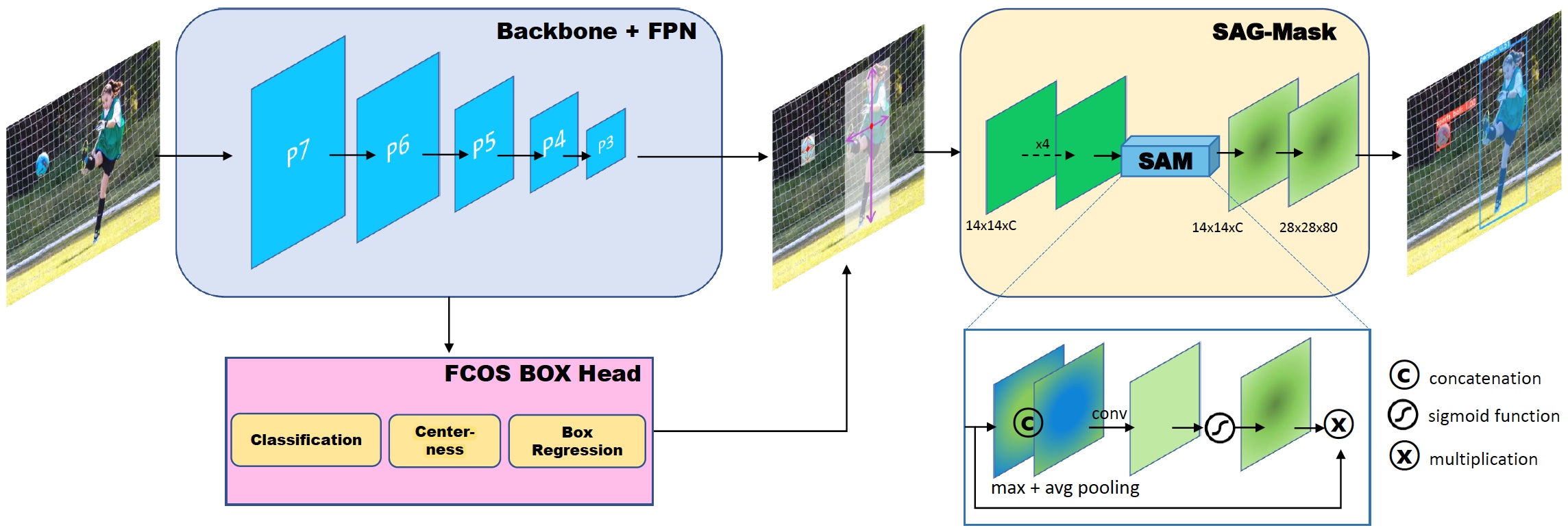
- 저자들은 아래 네 가지에서 novelty를 주장함
- SAG-mask
- spatial attention module (SAM)이 포함되어 있어서 informative pixel에 focus를 두고, noise는 suppress 하는 효과가 있음
- Predicted RoI(detection result)에 대해서 RoIAlign하여 14x14 크기로 축소된 feature map이 input으로 사용됨
- spatial attention map
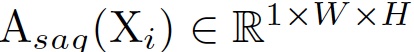 는 아래 과정으로 계산됨
는 아래 과정으로 계산됨

- Backbone 모델로 VoVNetV2를 제안함
- VoVNet은 one-shot aggregation (OSA) 모듈을 쌓은 모델임
diverse receptive fields를 커버하면서도 computation & energy efficient해서 resnet과 densenet보다 빠르고, 정확도가 높다고 설명함
- VoVNet의 저자가 이 연구의 저자임.
- 기존 VoVNet에 residual connection 추가하여 모델을 deep 하게 쌓을 수 있게 함
- 기존 VoVNet의 SE block이 2 개의 FC layer로 구성되어있는데, 이를 1개의 FC layer로 교체한 eSE block을 사용하도록 제안하여 channel information loss를 줄이고 결과적으로 정확도가 올라갔다고 함
- Table4를 보면 1.0 mAP 정도 정확도가 향상됨
- 단점은 eSE block이 파라미터 수가 SE block을 사용할때 보다 많음
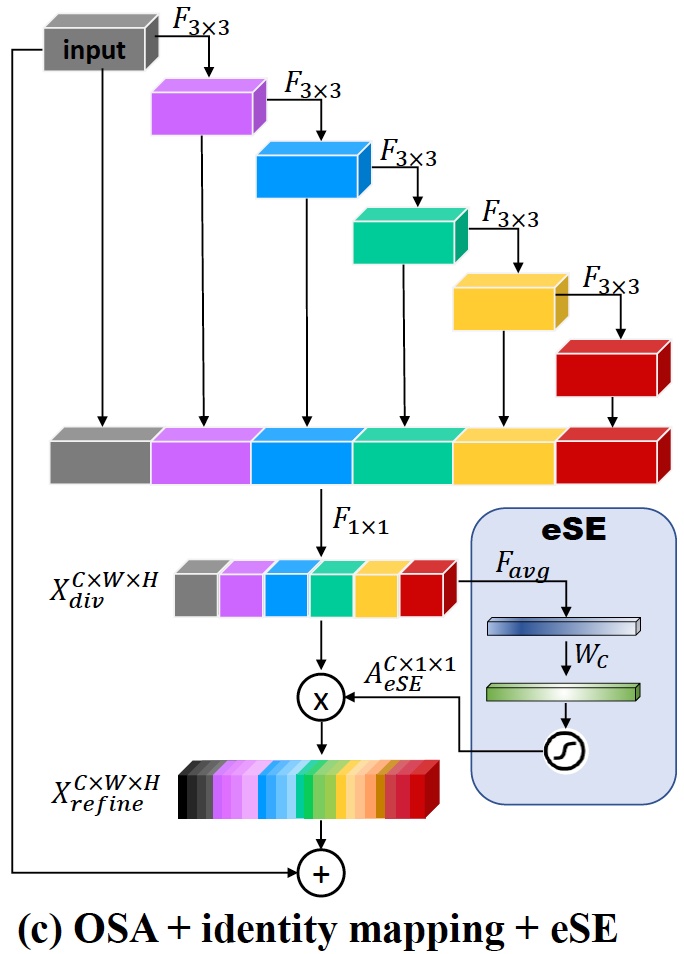
- VoVNet은 one-shot aggregation (OSA) 모듈을 쌓은 모델임
diverse receptive fields를 커버하면서도 computation & energy efficient해서 resnet과 densenet보다 빠르고, 정확도가 높다고 설명함
- Adaptive RoI Assignment
- One stage detector에 적합한 RoI assignment 방법
- 기존 RoIAlgin에서 input size에 따라 roi scale 변수 K를 조절 할 수 있도록 함
- small object에 대한 검출 성능이 좋아졌다고는 하는데 증거가 없음
- 증거로 제시한 Tabel.3는 포인트가 살짝 다른 느낌
- ablation study 결과 기존 RoIAlign 보다 약간 더 좋은 수준의 결과를 보임 (table.3)
- small object에 대한 검출 성능이 좋아졌다고는 하는데 증거가 없음
- CenterMask-Lite 모델을 제안하여 Real-time (30fps)를 달성함
- 단순히 모델 파라미터 수를 절반씩 줄인 것으로 생각되는데 코드를 확인해봐야겠음…
- 속도가 빨라지는 대신 성능은 많이 떨어짐
- SAG-mask
[Strengths]
- 높은 성능 (2019~2020 초반까지 instance segmentation 분야에서 SOTA 달성)
- 당연하겠지만 mask branch를 사용하게 되면서, detection 성능이 기존 FCOS보다 올라가는 것이 확인됨
- deploy 시 lite 버전도 고려할 수 있음
- 바로 사용해볼 수 있는 코드가 있음
[Weaknesses]
- Mask RCNN과 비교했을 때 dramatic한 차이가 벌어지지는 않음
- 논문에서는 COCO만 제시를 하였는데, 데이터셋에 따라서 Mask RCNN이 더 좋을 가능성도 존재할 것 같다고 생각함
- Adaptive RoI Assignment가 small object 검출 성능에 영향을 주는지는 검증이 필요함
[Codes]
- https://github.com/youngwanLEE/CenterMask (pytorch)
- https://github.com/youngwanLEE/centermask2 (pytorch)
- detectron2 위에서 다시 구현한 centermask