Swin Transformer: Hierarchical Vision Transformer using ShiftedWindows
[Summary]
- https://arxiv.org/abs/2103.14030
- Swin Transformer 는 Transformer를 vision application (classification, object detection, segmentation)에 적합하게 수정한 효과적인 방법이다.
- Transformer는 sequential한 데이터의 처리에 특화되어 language 모델에 많이 사용되었으며 뛰어난 성능으로 주목받는다.
- Transformer를 image domain에 적용하기 위한 다양한 시도가 있었고, input image를 grid 형태의 patch로 나누어 sequential하게 transformer에 전달하는 ViT, Deit 등의 방법들이 좋은 성능을 보였다.
- Swin Transformer는 text 와 image 분석의 다른 점이 ‘large variations in the scale of visual entities and the high resolution of pixels in images’ 임을 강조하며, grid를 아래 그림과 같이 계층적으로 구성하면 정확도와 처리 효율 모두를 개선할 수 있음을 주장한다.
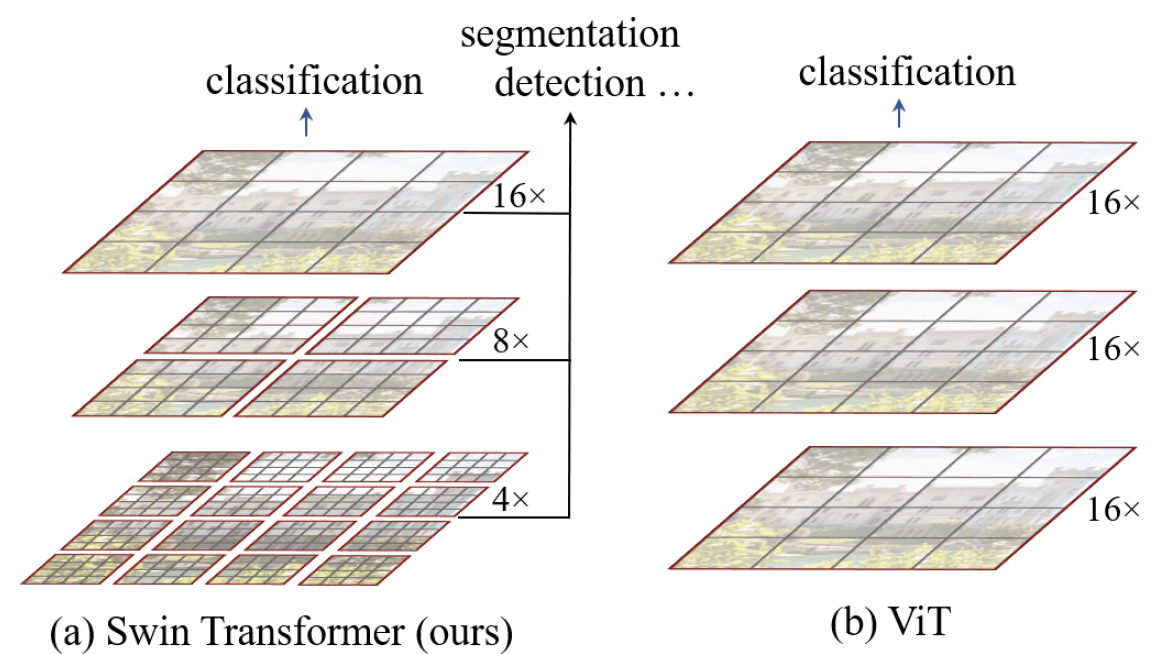 그림 1. Swin Transformer와 ViT의 feature map 구조 비교
그림 1. Swin Transformer와 ViT의 feature map 구조 비교
- Swin Transformer의 overall architecture
-
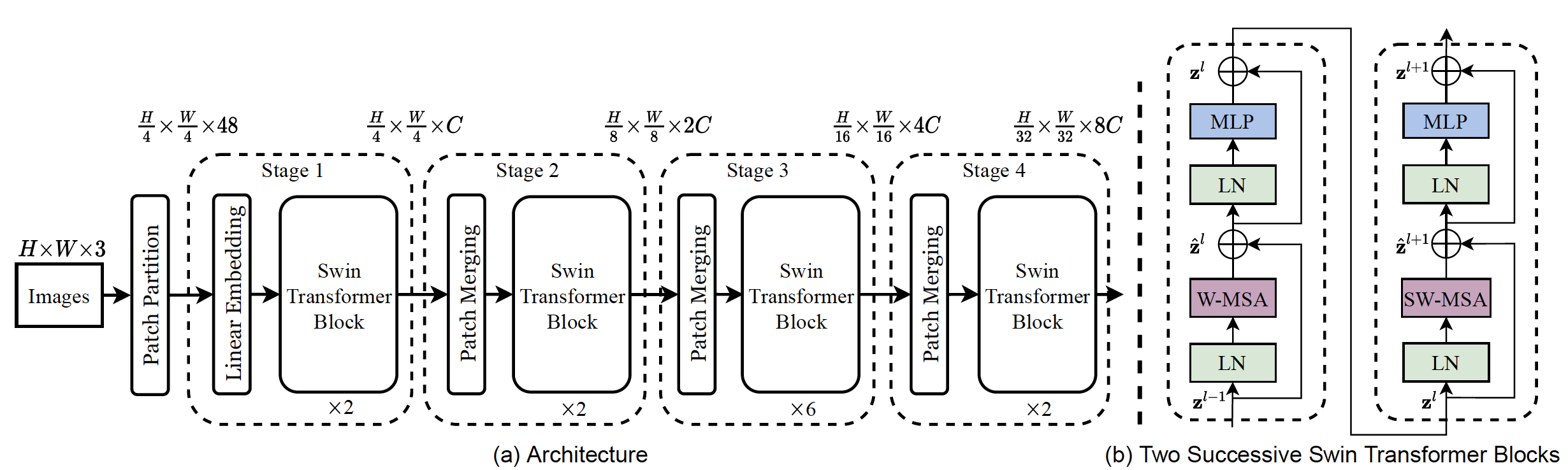 그림 2. Swin Transformer의 모델 구조
그림 2. Swin Transformer의 모델 구조 -
그림2는 Swin Transformer의 모델 구조와 transformer block을 묘사하고 있다.
- 작은 size의 patch부터 시작하여 layer가 deep 해질수록 이를 merge한 patch 들을 통해 self attention을 계산하도록 하여 알고리즘 복잡도를 줄였다.이는 마치 CNN 기반의 모델이 conv layer를 거치면서 계층적인 feature map을 추출할 수 있는 것과 유사한 특징을 갖게 한다.
- patch partition layer에서는 가장 작은 grid 단위로 image를 partition 한다. 이 patch 들은 ‘Token’으로 간주된다. (본 논문에서는 4x4 크기의 patch를 사용하였다.)
- linear embedding layer에서는 앞단의 feature를 임의의 크기의 dimension ‘C’으로 projection 시키는 역할을 한다.
- ‘Token’의 수는 patch merging layer 를 통해 downsampling 된다. patch merging layer에서는 2x2 neighboring patch 를 concat 한 뒤 linear layer에 통과시켜 resolution이 2x downsample된 2’C’ dimension의 output feature map을 형성한다.
- Swin Transformer block에서는 두 개의 연속된 Swin Transformer block이 적용되며, 각 patch에 대한 attention을 연산한다.
- 첫 번째 transformer block에서는 window based self-attention 이 계산되고, 두번째 block에서 shifted window based self-attention이 적용된다.
-
- Swin Transformer의 주요 contribution은 두 가지이다.
- Shifted window based self-attention을 제안하였다.
- Shifted window based self-attention은 아래의 두 concept에 의해 구현된다.
- Self-attention in non-overlapped window
- Self-attention을 image 전체 영역이 아닌 local window 별로 계산하도록 하여 효율을 늘림. 아래는 기존 self-attention과 window based self-attention의 계산식. window 내에는 MxM개의 patch 가 존재한다. W-MSA의 경우 M이 고정되었다고 생각하면, hw에 linear하다.
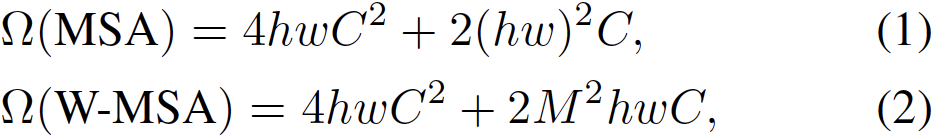
- Shifted window partitioning in successive blocks
- window based self-attention은 window 간의 관계를 고려하지 못한다는 단점이 있다.
- 제안하는 shifted window 는 서로 다른 window partitioning 방법을 두 번 적용하는 방식으로 모델이 cross window connection 고려할 수 있도록 하였다. (그림.2 (b)) 예를 들면, 첫번째 적용하는 window partitioning이 top left corner부터 시작하였다면, 두 번째 적용하는 window partitioning은 이전 layer의 (M/2, M/2) pixel 만큼 shift 하여 partition을 하는 것이다. 아래 그림.3은 이를 묘사한 것이다.
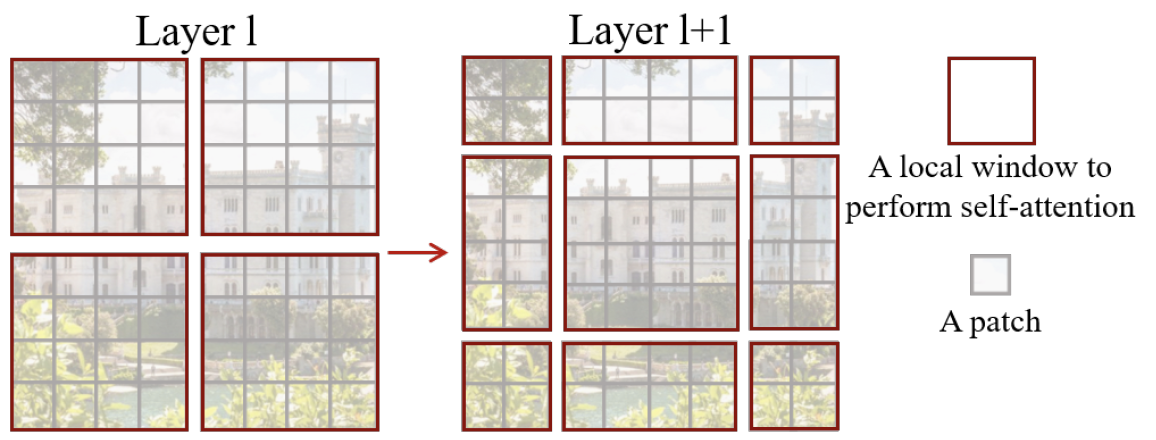 그림 3. Shifted window의 예시
그림 3. Shifted window의 예시
- 위 그림과 같이 window 크기가 MxM 보다 작은 경우에도 효율적인 계산을 위해서 본 논문에서는 cyclic-shift 를 적용하여 latency를 줄였다. (그림.4)
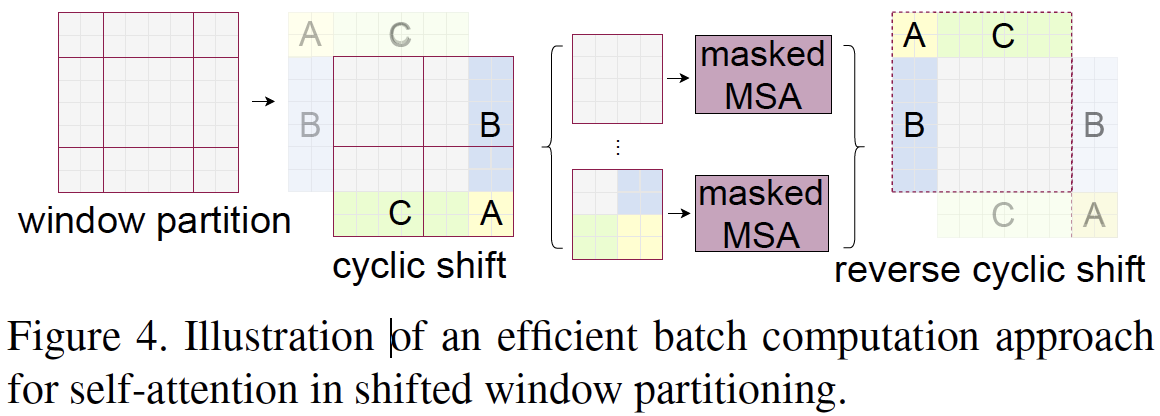
- Ablation study
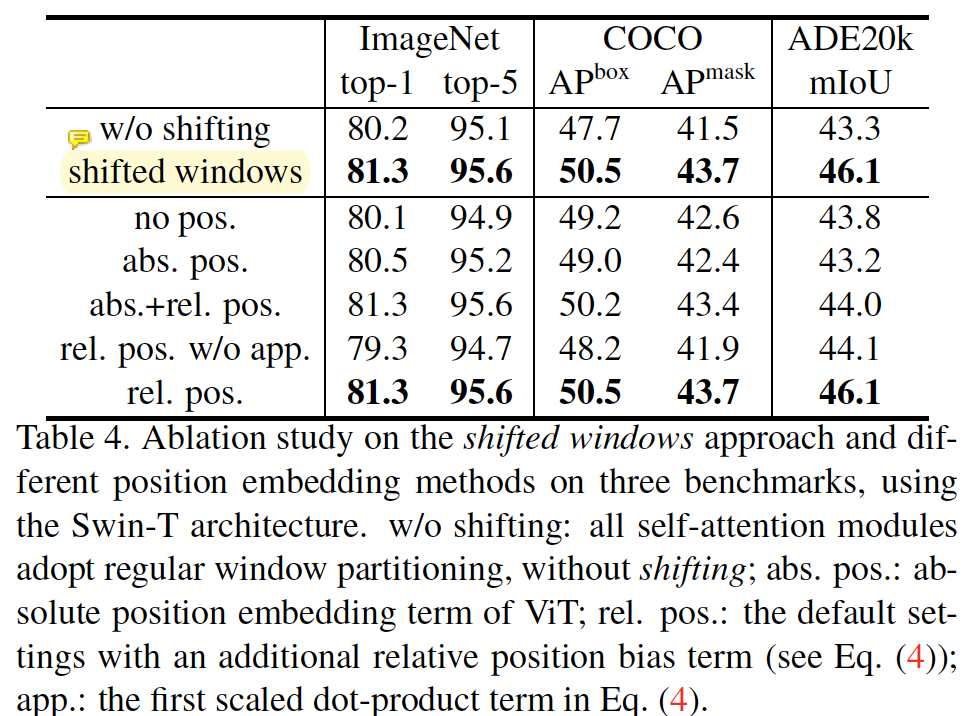
- shifted window에 의한 성능 향상이 있음을 ablation study를 통해서 보였으며, image classification, object detection, semantic/instance segmentation 모두에 적용될 수 있음을 보였다. 다양한 vision task에 general-purpose backbone으로 사용될 수 있다. swin transformer block은 conv layer의 feature output 과 유사하게 feature map resolution을 줄이는 특성이 있기 때문에, 기존의 잘 알려진 backbone network의 블록을 쉽게 대체할 수 있다.
- Self-attention in non-overlapped window
- 다양한 vision task에 general-purpose backbone으로 사용될 수 있다.
- swin transformer block은 conv layer의 feature output 과 유사하게 feature map resolution을 줄이는 특성이 있기 때문에 기존의 잘 알려진 backbone network의 블록을 쉽게 대체할 수 있다.
- Shifted window based self-attention은 아래의 두 concept에 의해 구현된다.
- Shifted window based self-attention을 제안하였다.
[Strengths]
- COCO Detection, Segmentation 부분에서 현재 (21.06.02) SOTA 모델이다.
- 결과를 보면 cls. 보다는 detection, segmentation에서 더 효과가 극명히 나타나는 것 같다.
- Transformer 계열의 방법을 고려했을때 처리 속도가 빠른 편이다 (12~22 FPS)
- Performer는 잘 모르지만 효율적으로 구현한 transformer 모델인 것 같고, 이보다 더 빠르다고 주장하고 있다.
- 구현체가 잘 공개되어 있다.
[Weaknesses]
- Shifted window layer의 갯수에 따른 성능 비교가 더 있었으면 좋았을 것 같다는 생각이 든다.
- COCO 에서 segmentation 성능이 가장 잘 나온 모델이 Swin L + HTC 모델인데 이것은 아직 공개가 되지 않았고, Cascaded Mask R-CNN 모델만 공개가 되어있다.
- Transformer 계열이다 보니 학습이 오래걸릴 것으로 예상된다.
- Shifted window를 통해 multi-scale feature map을 추출할 수 있는 구조를 제안한 것 외에 다른 이론적인 support가 약하다.
[Codes]
- https://github.com/SwinTransformer/Swin-Transformer-Object-Detection (pytorch)
- PyTorch 1.3+, mmdetection 위에서 구현
Comments